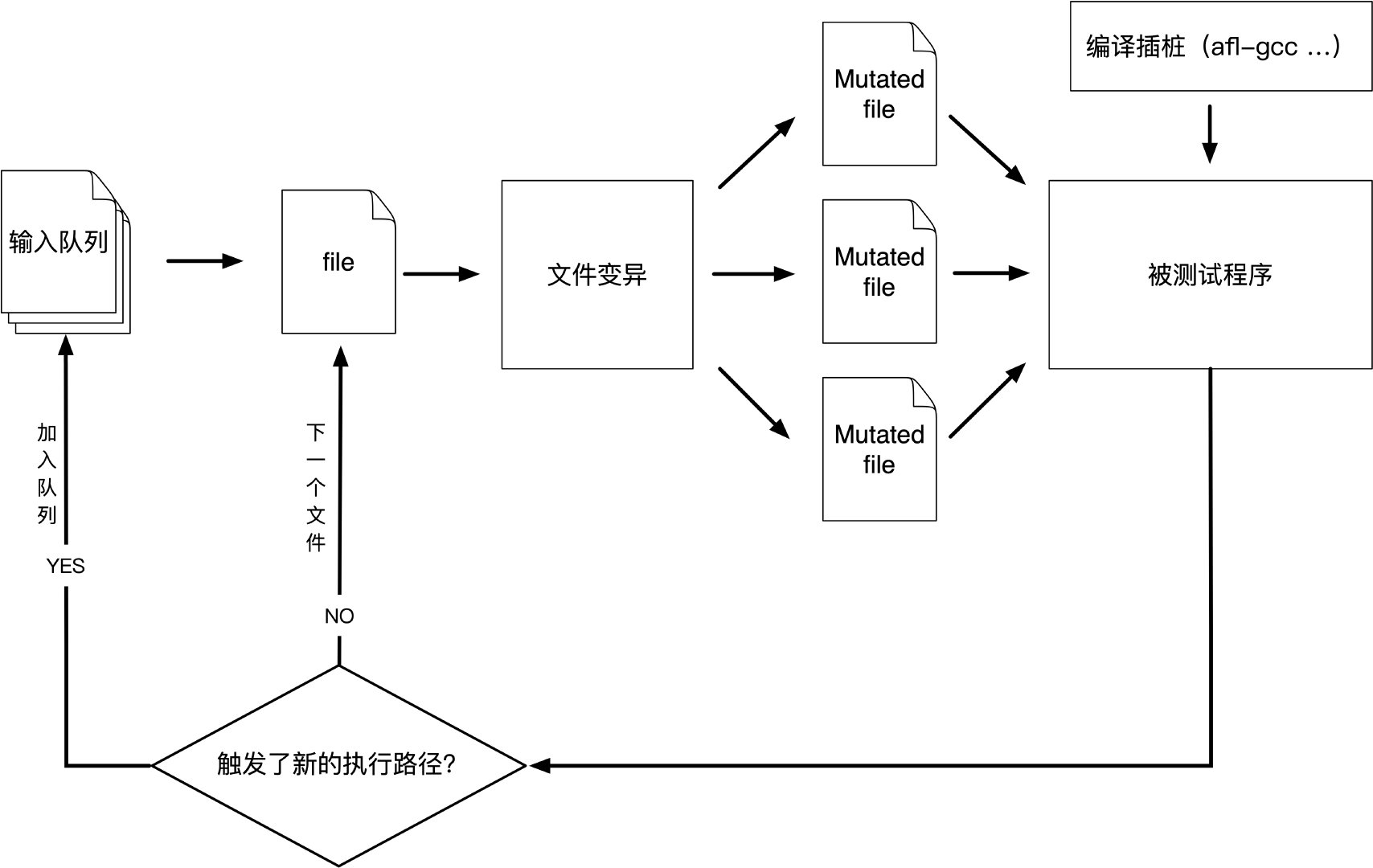
AFL(american fuzzy lop)最初由Michał Zalewski开发,和libFuzzer等一样是基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。其工作流程大致如下:
- 从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage)
- 选择一些输入文件,作为初始测试集加入输入队列(queue)
- 将队列中的文件按一定的策略进行“突变”
- 如果经过变异文件更新了覆盖范围,则将其保留添加到队列中
- 上述过程会一直循环进行,期间触发了crash的文件会被记录下来
1. 编译安装
GitHub仓库地址和 官网地址都只是提供了AFL的源码包,没有已编译好的二进制安装包,下载解压之后直接sudo make install便可以将之安装到系统目录了,网上找到的教程也多是说使用这种方法。
但我个人感觉这种方法并不是很好,首先安装不方便不说,然后Make过程指不定就容易出幺蛾子(一般容易缺少一些库),再后官方Makefile并没有uninstall目标,卸载也是麻烦,最后以后升级也必须手动操作。、
同时,我再ubuntu软件源中搜索了一下,其中已经包含了AFL的二进制deb包了(其实debian软件源中也有),所以直接apt install afl才是真正方便的方法。
除了afl包外,ubuntu仓库中还收录了afl-clang以及afl-cov包,后两者相对与前者只是一个补充,提供了更多的命令。
| 包名 | 提供的命令 |
|---|---|
| afl | afl-analyze afl-cmin afl-fuzz afl-gcc afl-gotcpu afl-plot afl-showmap afl-tmin afl-whatsup afl-g++ |
| afl-clang | afl-clang-fast afl-clang afl-clang++ afl-clang-fast++ |
| afl-cov | afl-cov |
基本AFL中相关的命令都包括了,现在版本也跟进到了官方最新的2.52b版本。
当然这一切只是建立在希望安装官方原版AFL的基础上的,如果需要对AFL进行魔改,当然还是需要下载源码进行make。
2. Hello, AFL
直接进行一个简单的AFL实验了解其使用流程。
2.1. 准备被测程序
首先创建一个简单的hello.c源文件,其功能无外乎接受一行命令行输入(一个整数、一个字符、再一个整数),然后根据中间这个字符当作运算符,输出四则运算结果。
|
可以看见,这个被测程序的内容和普通的用户交互程序一模一样,看不出来任何不同,就是以stdin/stdout作为交互的输入输出,以main函数作为执行入口。这就比libFuzzer要方便一点了,``libFuzzer还需要手动编写一个int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size)`函数作为接口作为Fuzz的入口。
2.2. 插桩编译
编译过程和普通gcc编译也是一样,除了使用的命令需要带上afl-前缀,因此
afl-gcc -o hello hello.c |
因为实际上afl-xxx系列命令本质上也就是给gcc、g++、clang之类的套了一层壳,各种参数选项的用法当然也就一致了。
如果被测程序是比较复杂的,并且提供了Makefile,实际上需要坐的工作便也是修改Makefile中的CC和CXX变量罢了。
2.3. 准备种子语料库
作为模糊测试,AFL需要提供初始的种子输入。
但实际上,你完全可以提供任何无意义的输入作为种子,模糊测试也一般能达到效果,只不过效率会低一些而已,是否提供有意义种子?提供多少?无外乎在种子获取难度和测试的效率要求之间进行权衡而已。
这里我们生成一好一坏两个种子语料库。
mkdir good-seeds bad-seeds |
2.4. 开始测试
执行命令,
afl-fuzz -i good-seeds/ -o good-outputs -- ./hello |
但是不出意外命令会报错,
[-] Hmm, your system is configured to send core dump notifications to an
external utility. This will cause issues: there will be an extended delay
between stumbling upon a crash and having this information relayed to the
fuzzer via the standard waitpid() API.
To avoid having crashes misinterpreted as timeouts, please log in as root
and temporarily modify /proc/sys/kernel/core_pattern, like so:
echo core >/proc/sys/kernel/core_pattern
[-] PROGRAM ABORT : Pipe at the beginning of 'core_pattern'
Location : check_crash_handling(), afl-fuzz.c:7275以及
[-] Whoops, your system uses on-demand CPU frequency scaling, adjusted
between 781 and 4003 MHz. Unfortunately, the scaling algorithm in the
kernel is imperfect and can miss the short-lived processes spawned by
afl-fuzz. To keep things moving, run these commands as root:
cd /sys/devices/system/cpu
echo performance | tee cpu*/cpufreq/scaling_governor
You can later go back to the original state by replacing 'performance' with
'ondemand'. If you don't want to change the settings, set AFL_SKIP_CPUFREQ
to make afl-fuzz skip this check - but expect some performance drop.
[-] PROGRAM ABORT : Suboptimal CPU scaling governor
Location : check_cpu_governor(), afl-fuzz.c:7337具体原因上述信息已经提到了,大致就是AFL测试时用到功能需要还没有开启,因此,切换到root用户执行上面报错中给出的命令即可。不过因为上述命令中修改的都是/proc和/sys目录下的文件,二者Linux内核映射出来的逻辑文件,并非实际的磁盘文件,重启之后所有修改都会丢失,避免麻烦还是将这几个语句保存成为脚本有利于重复执行。
echo core | sudo tee /proc/sys/kernel/core_pattern |
再次执行命令,
afl-fuzz -i good-seeds/ -o good-outputs -- ./hello |
可以正常运行,输出一段信息后呈现如下界面,表示fuzz已经开始了,可以在该界面中查看运行时间、崩溃数量等信息。
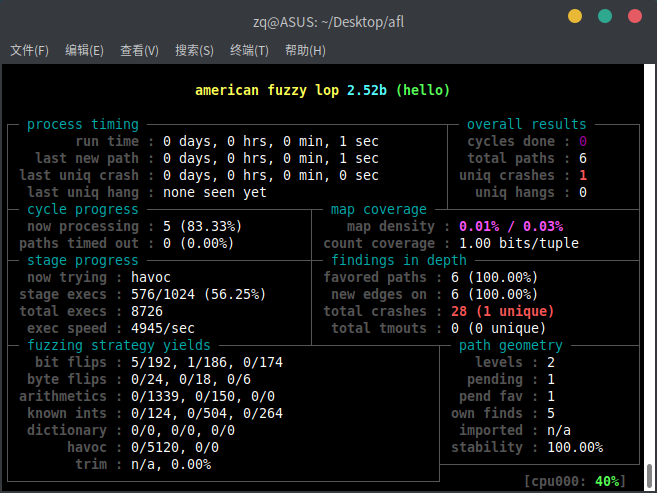
上图中显示已经找到了一个crash了,ctrl-C结束fuzz,可以看到当前目录下已经多出了good-outputs目录,这是本次模糊测试的结果。
引起崩溃的测试样例会位于good-outputs/crashes文件夹下,文件名大致形如id:000000,sig:08,src:000003,op:flip1,pos:2,本次测试中,获得的崩溃样例的内容为:
00000000: 312f 300a 1/0.其中包含1/0三个可打印字符和一个换行符。并未出乎意料,就是这种输入会导致程序中发生除零意外。
另外,还可以对另一个坏种子语料库重复实验
afl-fuzz -i bad-seeds/ -o bad-outputs -- ./hello |
结果照样能找到类似的引发除零错误的样例,只不过这次消耗的时间在10秒左右,要知道利用前面那个优质种子只用了1秒钟。
3. 编译全过程
这里主要从AFL和libFuzzer的差异角度进行对比。具体过程不表,直接放结论。
对于汇编过程,如果开启gcc的-S选项对比afl-gcc与普通gcc的汇编结果差异,可以发现进而libFuzzer原理一样,AFL在各种分支跳转指令处进行了插桩,使得程序的执行路径可以被追踪。
对于编译过程,发现afl-gcc产生的.o目标文件比普通gcc会多出来引用一些函数如getenv、fork、waitpid之类的,不过这些都是系统标准库中的函数,从这些函数看来是与进程控制相关,向来也是模糊测试所需,不在意料之外。这就和libFuzzer不同,libFuzzer会把一些非系统的(也就是由libFuzzer)提供的库函数声明到目标文件中。
对于链接阶段,承前结论,因为只使用了系统标准库,所以只需要使用系统链接器便可以完成程序的链接,估计这也就是为什么AFL中不提供afl-ld之类的链接器的缘故吧。
4. 测试执行
对于AFL,其编译后的结果是一个普通的执行文件,就拿前面我们所得到的hello可执行文件举例,其大可以直接在命令行使用./hello启动运行,然后此时你需要在终端进行输入(如1+1),然后又会在终端获得输出(如2)。
这看起来应该又算是一个领先于libFuzzer的地方了,libFuzzer会把整个程序改装层一个具有特定命令行模式的“测试器”,整个可执行程序已经不能直接执行原本的功能了。而AFL得到的可执行程序虽然进行了插桩,但依然能想未插桩那样发挥功能(,当然效率肯定低了,实际生产环境不推荐使用插桩后的程序)。
既然程序还是具有原功能的程序,那就需要使用额外的测试器了,那就是afl-fuzz了。其使用方式为:
afl-fuzz [ options ] -- /path/to/fuzzed_app [ ... ]
Required parameters:
-i dir - input directory with test cases
-o dir - output directory for fuzzer findings
Execution control settings:
-f file - location read by the fuzzed program (stdin)
-t msec - timeout for each run (auto-scaled, 50-1000 ms)
-m megs - memory limit for child process (50 MB)
-Q - use binary-only instrumentation (QEMU mode)
Fuzzing behavior settings:
-d - quick & dirty mode (skips deterministic steps)
-n - fuzz without instrumentation (dumb mode)
-x dir - optional fuzzer dictionary (see README)
Other stuff:
-T text - text banner to show on the screen
-M / -S id - distributed mode (see parallel_fuzzing.txt)
-C - crash exploration mode (the peruvian rabbit thing)重点关注-i和-o两个选项,用来指定种子语料库目录与结果输出目录,前者需要预先创建并在其中放置至少一个非空的种子。
然后是--双横线之后的内容,双横线之后是可执行程序的启动命令。换句话说,这些个内容将会在被测程序的main函数中以argv[0], argv[1], ..., argv[argc]的形式呈现。
那模糊测试产生的输入样例呢?
libFuzzer将输入样例作为一个字节数组,并将它的指针与长度传入给接口函数。AFL采用了另一种思路,将之视为文件!
像前面的例子,这个文件就是stdin标准输入,afl-fuzzer把标准输入重定向到其产生的测试样例,这样在程序中scanf/cin就相当于在利用测试样例了。
另外如果有其他需要?譬如读取的是二进制格式的输入而非终端字符。
办法之一就是使用C标准库的freopen函数将标准输入以二进制文件的形式打开,然后使用fread等函数对之进行读取。
另一个办法就是在命令行的--后程序参数中加一个@@,这是一个占位符,AFL发现这个占位符就不会把测试样例重定向给stdin,转而将值保存为一个磁盘文件,然后在main函数中,@@占位符对应的argv就是该文件的路径字符串,读取之即可。
5. 循环vs进程
还是拿libFuzzer进行对比,libFuzzer将整个被测对象视为一个函数接口,每次测试视为循环体中对函数的一次调用。但是AFL不然,他将被测对象看作一个可执行程序,每次测试视为对程序的一次调用,自然也会在新的进程环境中。
一个直观的对比实验就是,在函数体类建立一个初始为0的static的静态变量,并且在后面加一个对其进行加一操作,如果是函数的循环调用,那么最终这个变量的值会不断地被累加上去,而如果是程序的多次调用,由于每次都在一个新的进程环境,那么每次都是0+1=1。观察实验结果就可知libFuzzer是前者,而AFL是后者。
其优势劣势显然也可以揣测一二了,循环调用的方法肯定效率特别高,但是总需要顾忌对全局环境的“污染”,很可能某一次崩溃并非由于单独输入数据引起,而是由于之前的测试样例导致全局变量被修改共同引起。对于实际的复杂模块,不使用全局变量是不可能的,排除全局“污染”的干扰也是很难实现。高效的代价就是局限性了。
而AFL反之,低效,但是更加普适稳定。不过AFL还是努力在提升了效率的,因为在测试过程中就能发现,可执行程序始终复用同一个进程号,而不是简单地fork,一次一个。
6. 再与libFuzzer对比
前面已经将AFL和libFuzzer进行了很多对比了,整体看起来除了效率方面AFL似乎更胜一筹了。
另外还没提到的就是测试控制参数方面,libFuzzer接受的参数更多一些,可以对整个fuzz过程进行能加细节地控制,应该则还是一个效率优势。
不过中的感觉libFuzzer全局“污染”问题还是一个很难过去的坎,怪不得看到的文章似乎都以AFL作为测试框架(,好吧,虽然自己确实也没看几篇文章,采样率太低)。